
Проблемы технического SEO: выявить и устранить (часть 2)
Очень распространена ситуация, когда сайт продвигался в разное время разными компаниями или собственными силами. Развиваются поисковые системы — развивается и SEO. Какие-то приемы работы устаревают, какие-то остаются актуальными, но бывает такое, что атрибуты от устаревших методов продвижения мешают сайту в настоящем. Поэтому наши специалисты сначала проводят аудит сайта, а потом предлагают стратегию продвижения, основываясь на самых актуальных тенденциях.

9. Атрибуты hreflang некорректны или недействительны
В чем проблема?
Прекрасно, если у вас есть возможность расширить свою аудиторию за счет локализации. То есть если ваш сайт заточен под несколько языков. С одной стороны, это прекрасно для SEO, с другой — требует большой внимательности для специалистов при оптимизации.
Для многоязычных сайтов используется атрибут hreflang и это сложный аспект, в котором очень легко ошибиться. Среди самых распространенных ошибок:
- атрибутов hreflang вообще нет на мультиязычном ресурсе;
- нет тегов возврата hreflang;
- использовано несколько методов для указания атрибутов hreflang: в файле sitemap, заголовке HTTP, в разделе ;
- атрибуты hreflang конфликтуют между собой;
- аннотации hreflang недействительны, то есть коды регионов или языков неправильно указаны;
- атрибуты hreflang указывают на проблемные URL: те, что возвращают четырехсотые и пятисотые ошибки, или на переадресованные, вместо целевых;
- аннотации hreflang указывают на каноникализированные URL, или на ссылки, закрытые с помощью disallow или noindex.
- нет атрибута x-default.
Цена любой из этих ошибок — понижение позиций в поисковой выдаче.
Как решить проблему?
Проверьте работают ли атрибуты hreflang правильно. Для этого используйте Search Console и отчет «Таргетинг по странам и языкам». Шпаргалка по правильным настройкам:
- атрибуты hreflang валидны;
- атрибуты указывают на канонические URL, возвращающие 200 (ОК)
- есть теги возврата hreflang;
- прописан атрибут x-default.
10. Наличие дублей страниц
В чем проблема?
Если ваш проект содержит нечто вроде интернет-магазина с возможностью настройки отображения карточек и разными фильтрами параметров, то от технического дублирования контента вам не уберечься. Это не единственный вариант, когда появляются дубли — такое бывает и из-за версий для печати, при использовании UTM-меток и так далее.
Проблемой это становится потому, что поисковые системы выделяют для каждого сайта ограниченный краулинговый бюджет. Это означает, что поисковой робот может “застрять” на дубликатах вместо того, чтобы индексировать действительно важные для продвижения страницы. То есть вместо повышения позиций, вы получите понижение с неясной перспективой. Конечно, поисковые алгоритмы совершенствуются, и Google в большинстве случаев справляется с ситуациями технического дублирования контента, но зачем гадать, если грамотный SEO-специалист может решить эту проблему, используя тег canonical.
Как решить проблему?
- Найдите дублированные страницы.
- Выберите основную версию страницы для дублей и скопируйте ее URL.
- Добавьте элемент link с атрибутом rel=canonical и указанием на основную версию URL на все дублированные страницы.
- Проверьте отчет об индексировании в Google Search Console — в разделе «Исключенные» появятся все дубли.
11. Ошибки в настройках канонических URL
В чем проблема?
Описывая предыдущую проблему, мы упомянули, что Google умеет справляться с техническими дублями. На практике это означает, что поисковой робот может и сам выбрать канонический URL. Это становится проблемой, если у вас есть собственное представление о том, что нужно индексировать, а что нет. Но реализация канонических URL дело непростое, и некоторые SEO-специалисты могут совершить ряд ошибок, например:
- атрибут rel=canonical недействительный или вовсе пустой;
- атрибут указан не в разделе ;
- rel=canonical указывает на каноникализированный URL;
- канонический URL указывает на неверную страницу: на HTTP-версию, или страницу с тегом noindex, или заблокированную в robots.txt, или той, что возвращает четырехсотые или пятисотые ошибкие;
- канонического URL нет в исходном коде;
- канонические URL конфликтуют из расположения одновременно в разделе и в заголовке HTTP.
Как решить проблему?
- Просканируйте сайт, используя Screaming Frog или Sitebulb. Вы получите список страниц, с которыми надо поработать.
- Обновите атрибуты rel=canonical и проверьте, чтобы они указывали на правильные страницы.
12. Ненужные записи в файле Sitemap
В чем проблема?
К содержанию sitemap.xml следует подходить без фанатизма. Не нужно, чтобы в нем хранились все-все URL вашего сайта, потому что тогда поисковым роботам придется обходить их все, а мы уже знаем о том, что у них тоже есть бюджет — краулинговый. Это значит, что если в sitemap.xml будет полный список всех URL, то ваш сайт может потерять в позициях, потому что робот не успеет обойти все значимые страницы.
Как решить проблему?
Просканировать сайт на предмет ненужных записей. Файл sitemap.xml генерируется автоматически, поэтому SEO-специалисту необходимо уточнить правила его создания. Нужно почистить sitemap.xml от следующих записей:
- ссылки, заблокированные в robots.txt;
- каноникализированные URL;
- ссылки с тегом noindex;
- переадресованные URL;
- ссылки, возвращающие четырехсотые и пятисотые коды ответа сервера;
- ссылки-дубли.
Если ваш сайт на Wordpress, то вам поможет плагин RankMath.
13. Невалидные HTML-элементы в разделе
В чем проблема?
Корректное оформление раздела
очень важно для оптимизации сайта. Если в нем будут допущены ошибки или будут размещены неправильные элементы, то это может слишком рано его закрыть для индексации или вовсе нарушить. Чревато это тем, что поисковые роботы пропустят очень важную информацию для высоких позиций в выдаче.Как решить проблему?
Проверить раздел
:- Если в нем есть тег noscript, то проверить, что его элементы только вида style, link и meta.
- Удалить из noscript в элементы типа img и h1.
14. Избыточная блокировка ресурсов сайта в файле robots.txt
В чем проблема?
Поисковые роботы визуализируют страницы сайтов для того чтобы более качественно сканировать содержимое страниц даже при обилии JavaScript. Соответственно, если вы блокируете их и CSS-файлы в robots.txt, то препятствуете корректной работе поисковика. Означает это только одно: возможны потери позиций в ТОПе.
Как решить проблему?
- Удалите из файла robots.txt директивы disallow, мешающие поисковым роботам сканировать сайт.
15. Сайт имеет низкие показатели Core Web Vitals в реальных условиях
В чем проблема?
Core Web Vitals — это относительная новинка от Google. Представляет собой совокупность характеристик удобства пользования страницей. Для поисковой системы Google важно выдавать в ТОП страницы, удобные для пользователя, чтобы тот провел на них как можно больше времени. И если не все параметры оптимизации известны даже самым опытным SEO-мастерам, то Core Web Vitals имеет вполне конкретные показатели, которые можно измерить и визуально представить.
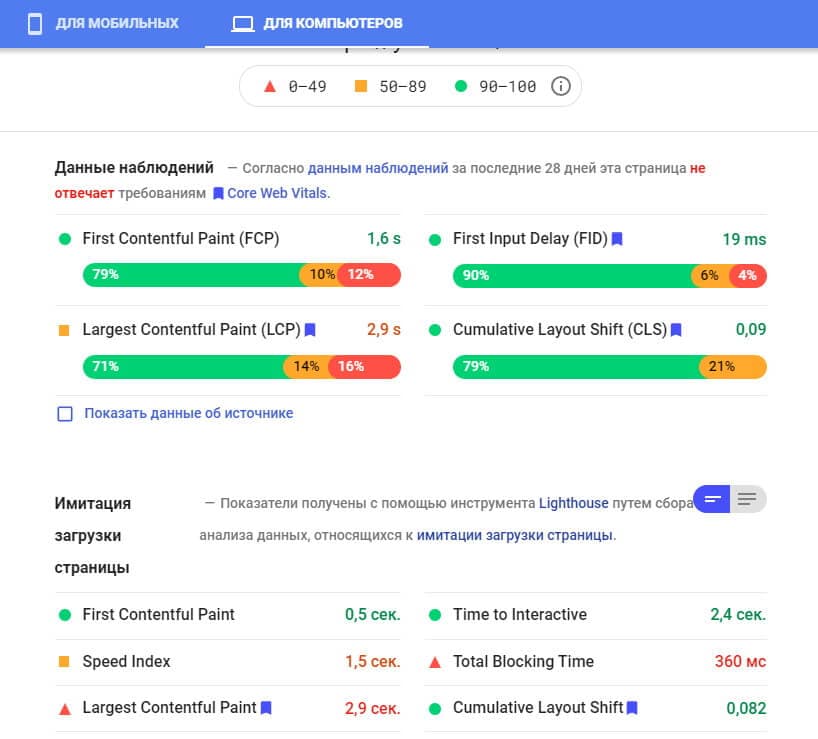
Подпись: И без слов понятно, что “зеленые” — хорошие показатели, а “красные” — плохие.
Три ключевых параметра Core Web Vitals:
- Largest Contentful Paint — показывает быстро ли загружается основной контент.
- First Input Delay — отражает то, как долго ли пользователю приходится ждать прежде чем начать пользоваться сайтом.
- Cumulative Layout Shift — демонстрирует насколько быстро встают на место смещающиеся элементы, такие как кнопки и всплывающие окна.
Core Web Vitals использует в своих оценках данные наблюдения за реальными пользователями на странице. Иногда бывает, что данных не хватает, и тогда он выдает оценочные данные:
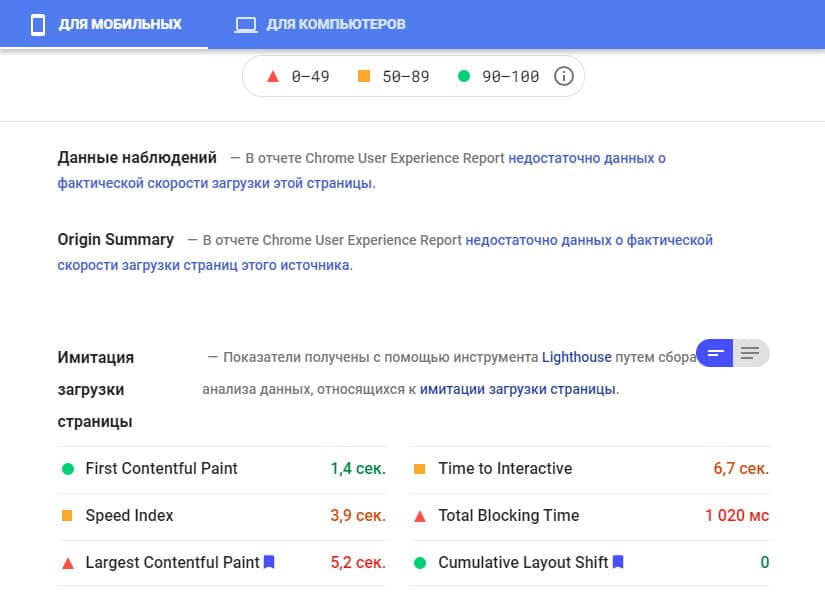
Подпись: Когда данных от реальных пользователей недостаточно, Google рассчитывает оценки имитируя загрузку страницы.
Проблема в том, что реальные и оценочные данные всегда разные. Может быть такое, что при имитации показатели высокие, а в реальности — низкие. Возможна и обратная ситуация, но такое бывает реже. Так что, если недостаточно реальных данных, а оценки сайта по имитации загрузки страницы достаточно высокие — это совсем не значит, что они таковы на самом деле. Поэтому если у вас недостаточно реальных данных, то ориентироваться на показателях имитации может оказаться весьма самонадеянно. Нужно стремиться к лучшим показателям, а не просто попадающим в “зеленый” диапазон.
Как решить проблему?
- Используйте Search Console отчет об основных интернет-показателях и проанализируйте все перечисленные проблемы;
- Запустите проверку в PageSpeed Insights для каждой проблемной страницы и изучите советы по ее оптимизации;
- Внедрите предлагаемые изменения для страниц и продолжайте использовать Core Web Vitals для отслеживания динамики в успешности оптимизации.
В этой статье мы перечислили 15 часто встречающихся ошибок в техническом SEO и дали подсказки как проверить есть ли они на вашем сайте и как их исправить, если обнаружите.
Инструменты для анализа SEO-показателей доступны:
- сервис Google PageSpeed Insights;
- сервис Google Search Console;
- приложение Sitebulb;
- краулер Screaming Frog SEO Spider.
Однако работа SEO-специалиста не завершается выявлением проблем и анализом. Важно предложить такие изменения, которые станут стратегией для повышения позиций сайта. Если ваш сайт уже “старожил” в интернете, то возможно наслоение предыдущих неудачных тактик, которые мешают продвижению в настоящем. Мы поможем разобраться во всех деталях и выведем ваш сайт в ТОП — обращайтесь!
Оставьте заявку, в течение 24 секунд мы свяжемся с вами, чтобы предложить вашему проекту лучшее решение!